
常见编程语言编译/执行流程
C/C++
编译过程
以下内容基于在 Linux 上使用 GCC (GNU Compiler Collection) 编译代码
一条简单的 gcc 编译命令背后包含了四个步骤:预处理 (Preprocessing)、编译 (Compilation)、汇编 (Assemble)、链接 (Linking)。

| 步骤 | 命令 | 等价命令 | 输出文件 |
|---|---|---|---|
| 预处理 | cpp | gcc -E | .i, .ii |
| 编译 | cc1, cc1plus | gcc -S | .s |
| 汇编 | as | gcc -c | .o, .obj |
| 链接 | ld | gcc | 可执行文件 |
以一个很小的示例分步骤演示上述编译过程,共有 main.cpp、my_math.h、my_math.cpp 3 个文件,其中 main.cpp 依赖 my_math.h。程序内容分别如下:
1 |
|
1 |
|
1 |
|
步骤1:预处理 (Preprocessing)
主要用于处理 # 开头的代码行,比如对宏做展开,对 include 的文件做展开,条件编译选项判断,清理注释等。文件以 .i 和 .ii 结尾。
执行
1 | cpp main.cpp -o main.i |
得到的 .i 文件内容非常多,例如 main.i 共有 896 行,这与代码展开有直接关系。main.i 内容结构如下,其中大部分内容都在 extern "C" 中:
1 | // 省略…… |
步骤2:编译 (Compilation)
使用预处理的输出结果作为输入,生成文本格式的平台相关的汇编代码 (assembly code)。文件以 .s 结尾。
执行:
1 | g++ -S main.i -o main.s |
或者直接使用cc1(用于C代码)或cc1plus(用于C++代码)。
注意cc1plus没有在bash默认的搜索路径中。
编译得到 main.s 文件,内容如下:
1 | .file "main.cpp" |
步骤3:汇编 (Assemble)
将上一步的汇编代码转换成二进制的机器码,称为 object code。产生的文件叫做目标文件,是二进制格式,文件以 .o 或 .obj 结尾。
执行:
1 | as main.s -o main.o |
编译后生成 main.o,这是个二进制文件,file main.o 命令查看文件属性:
1 | main.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped |
步骤4:链接 (Linking)
链接过程将多个目标文以及所需的库文件 (.so等) 链接成最终的可执行文件 (executable file)
执行:
1 | ld -plugin /usr/local/libexec/gcc/x86_64-linux-gnu/12.1.0/liblto_plugin.so -plugin-opt=/usr/local/libexec/gcc/x86_64-linux-gnu/12.1.0/lto-wrapper -plugin-opt=-fresolution=/tmp/ccIJ5Caz.res -plugin-opt=-pass-through=-lgcc_s -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lc -plugin-opt=-pass-through=-lgcc_s -plugin-opt=-pass-through=-lgcc --eh-frame-hdr -m elf_x86_64 -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o /usr/local/lib/gcc/x86_64-linux-gnu/12.1.0/crtbegin.o -L/usr/local/lib/gcc/x86_64-linux-gnu/12.1.0 -L/usr/local/lib/gcc/x86_64-linux-gnu/12.1.0/../../../../lib64 -L/lib/x86_64-linux-gnu -L/lib/../lib64 -L/usr/lib/x86_64-linux-gnu -L/usr/local/lib/gcc/x86_64-linux-gnu/12.1.0/../../.. -lstdc++ -lm -lgcc_s -lgcc -lc -lgcc_s -lgcc /usr/local/lib/gcc/x86_64-linux-gnu/12.1.0/crtend.o /usr/lib/x86_64-linux-gnu/crtn.o main.o my_math.o -o main |
得到可执行文件 main。
这步太长了,没有自己在电脑上尝试,直接照搬的原文。
All in One
1 | g++ main.cpp my_math.cpp -o main # 四合一编译命令。 |
不同C/C++编译器对比
内容来源:知乎-几大主流 C++ 编译器(ICC / GCC / Clang / VC++)究竟孰优孰劣以及MSVC,GCC,Clang——不同C/C++编译器对比
图片来源:Clang/LLVM compiler architecture
| C++编译器 | 编译器全称 | 支持的平台 | 备注 |
|---|---|---|---|
| MSVC | Microsoft Visual C++ | Windows | 由微软开发,主要用于 Windows 平台应用程序的开发。Visual Studio 系列 IDE 默认集成了该编译器 |
| GCC | GNU Compiler Collection | Windows, Linux, macOS | 开源编译器,支持多种平台,Linux 下 C++ 开发一般默认会使用此编译器 |
| Clang | Clang / Low Level Virtual Machine | Windows, Linux, macOS | LLVM 项目的一部分,提供高效的编译性能。macOS 的 XCode 工具默认集成了此编译器 |
MSVC
- MSVC (Microsoft Visual C++) 由微软开发,主要用于 Windows 平台应用程序的开发。
- Visual Studio 系列 IDE 默认集成了该编译器,可以通过下载安装 Visual Studio 安装包来安装。
- MSVC 只能在 Windows 下用,不支持跨平台。
工具链中的主要工具为:
| 工具 | 功能描述 |
|---|---|
| cl.exe | 编译程序 |
| link.exe | 链接程序 |
| lib.exe | 加载 lib 库的程序 |
| nmake.exe | 用 makefile 进行构建、编译的工具 |
GCC
GCC(GNU Compiler Collection)是由 GNU 项目开发的一套优化编译器,它支持多种编程语言、操作系统和计算机架构。作为自由软件,GCC 由自由软件基金会(FSF)在 GNU 通用公共许可证(GNU GPL)下分发。
GCC 最初名为 GNU C 编译器(GNU C Compiler),因为它最初只支持 C 语言。然而,不久之后,GCC 就扩展了对 C++ 的支持,并逐渐增加了对 Fortran、Pascal、Objective-C、Java、Ada、Go 等多种语言的支持。
GCC 不仅是 GNU 操作系统的官方编译器,也是许多类 UNIX 系统和 Linux 发行版的标准编译器。在 GCC 出现之后,BSD 家族的大部分操作系统也开始使用 GCC。不过,一些系统如 FreeBSD、OpenBSD 和 Apple 的 macOS 已经转而使用 Clang 编译器。
MinGW(Minimalist GNU for Windows)是将 GCC 编译器和 GNU Binutils 移植到 Windows 32位平台的项目。它包括了一系列头文件(用于 Win 32 API)、库和可执行文件。由于最初的 MinGW 项目更新缓慢,且不支持64位环境开发,OneVision Software 于2005年开始开发 MinGW-w64。MinGW-w64 支持 GCC 所支持的大多数编程语言,包括 C、C++、Objective-C、Objective-C++、Fortran 和 Ada。
GCC 中常用的工具有:
| 工具 | 描述 |
|---|---|
| gcc | GCC 的主要编译器,用于将源代码编译为可执行文件或库。支持多种语言(如 C、C++、Fortran 等),并提供丰富的编译选项。 |
| g++ | GCC 的 C++ 编译器,用于将 C++ 源代码编译为可执行文件或库。与 gcc 共享许多相同的编译选项,同时支持针对 C++ 的特定选项。 |
| gdb | GCC 附带的调试器,用于调试程序。允许在程序运行时设置断点、单步执行代码、查看变量值等。支持多种编程语言,提供强大的调试功能。 |
| objdump | 用于反汇编目标文件或可执行文件,显示二进制文件的汇编代码。还可显示符号表信息、重定位表等相关信息。 |
| nm | 用于列出目标文件或可执行文件中的符号表。显示函数、变量以及其他符号的名称和地址。 |
| ar | 用于创建、修改和提取静态库文件。允许将多个目标文件打包成一个库文件,以便在编译时链接使用。 |
| size | 用于查看目标文件或可执行文件的大小信息。显示代码段、数据段和符号表等各部分的大小统计。 |
| readelf | 用于显示 ELF (Executable and Linkable Format) 格式的二进制文件的详细信息。显示段表、符号表、动态链接信息等。 |
Clang/LLVM
Clang 是一个编译器前端,支持多种编程语言,包括 C、C++、Objective-C、Objective-C++,以及支持 OpenMP、OpenCL、RenderScript、CUDA、SYCL 和 HIP 等软件框架。它可以作为 GNU 编译器集合(GCC)的替代品,并且兼容 GCC 的大多数编译标志和非官方的语言扩展。Clang 使用 LLVM 作为其编译器的后端。
LLVM 是一套编译器和工具链技术,它允许开发者为任何编程语言创建前端,为任何指令集架构创建后端。LLVM 的设计核心是一种与语言无关的中间表示(IR),这种 IR 可以看作是一种可移植的高级汇编语言,它可以通过多次转换来进行优化。LLVM 项目始于 2000 年,在伊利诺伊大学厄巴纳-香槟分校由 Vikram Adve 和 Chris Lattner 领导。最初,LLVM 是作为研究静态和动态编程语言动态编译技术的研究基础设施而开发的。
2005 年,苹果公司聘请了 Chris Lattner 并组建了一个团队,致力于将 LLVM 系统应用于苹果开发系统中的多种用途。最初,LLVM 项目计划使用 GCC 作为前端,但由于 GCC 源代码庞大且实现复杂,加之苹果的软件大量使用 Objective-C,而 GCC 对 Objective-C 的支持优先级不高,以及 GCC 的 GNU 通用公共许可证(GPL)第 3 版要求分发 GCC 扩展或修改版本的开发者必须提供源代码,这与 LLVM 的宽松许可证不符。因此,苹果公司开发了 Clang,自 Xcode 4 起,苹果的默认编译器改为了 Clang/LLVM。

和 GCC 类似的,Clang 的编译流程为:
1 | # 预处理生成.i 文件。 |
或者
1 | # 将.c 文件编译成 LLVM 中间表示的汇编代码文件.ll,人类可读的中间表示形式。 |
然后使用 llc 将中间表示文件(.bc 或 .ll)转换为目标平台的汇编代码。
1 | # 这两种转换生成的汇编代码相同 |
最后转变为可执行的二进制文件:
1 | clang ./hello.s -o hello |
C# (.NET 框架)
.NET 编译过程详解
执行过程概述
- 开发者编写 C# 代码
- C# 编译器检查语法并分析源代码
- Microsoft 中间语言 (MSIL) 作为结果生成(EXE 或 DLL)
- CLR 在进程内部初始化并运行入口点方法(Main)
- MSIL 通过 JIT 编译器转换为本机代码

CLR 是什么
公共语言运行时(Common language runtime,CLR)是一个运行代码并提供服务的环境,使开发过程更加便捷。其功能具体为:开发者编写并且编译代码,接下来的步骤就由 CLR 负责——它将编译 MSIL(DLL 或 EXE)并创建一个执行代码的环境。
开发者可以使用任何想要的编程语言来开发代码,只要用于编译代码的编译器(例如 C++/CLI、C#、Visual Basic、F#)针对的是该运行时环境。“托管代码 (managed code)”这一术语指的是由运行时管理执行的代码。运行时负责接收托管代码,将其编译为本机代码,然后执行它。
运行时提供以下功能:
- 内存管理
- 安全边界
- 类型安全
- 异常处理
- 垃圾回收
- 性能改进
编译源代码

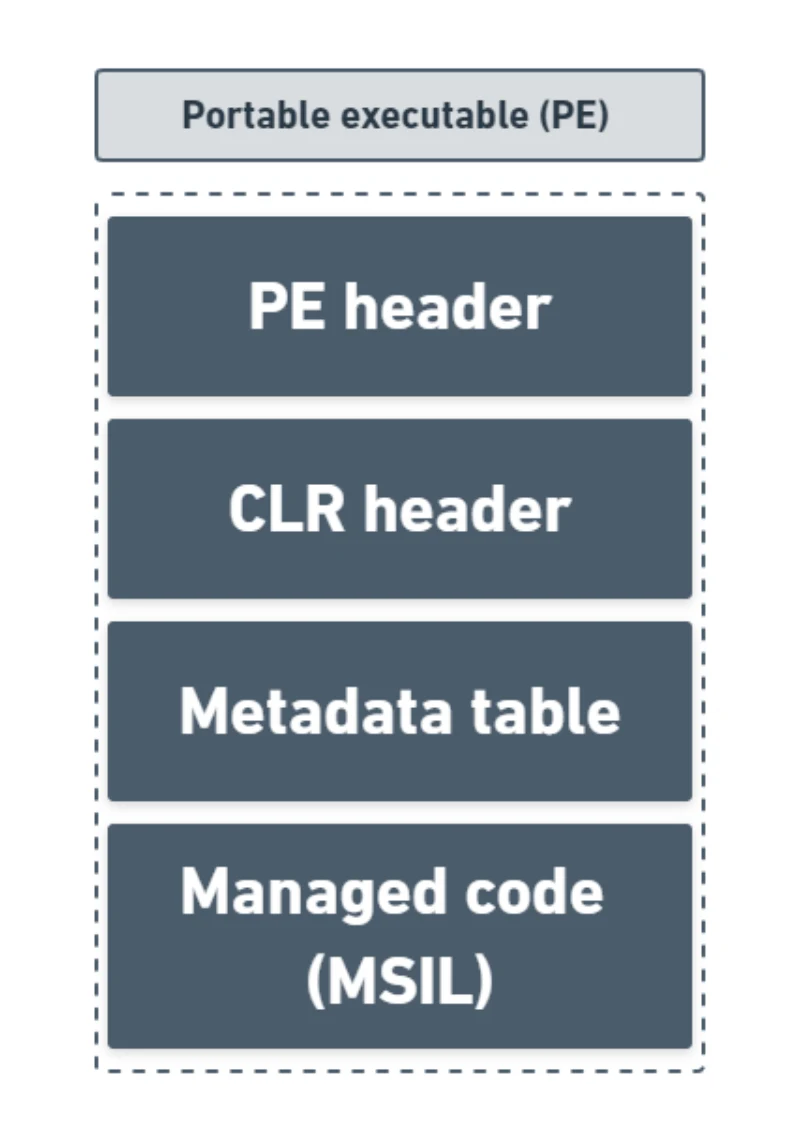
编译器得到的托管代码即为 MSIL (Microsoft intermediate language),这是一种与 CPU 无关的指令集,可以高效地转换为本机代码。无论使用什么编译器,其输出结果都是一个托管模块 (managed module),这是一个 32 位或是 64 位的 Windows 可移植可执行文件 (Windows portable executable file),简称分别为 PE32 或 PE32+。
其中一个托管模块的内部包含:
- PE 头 (PE header) - 如果头文件采用 PE32 格式,则该文件可在 32 位或 64 位版本的 Windows 上运行。若头文件采用 PE32+格式,则文件需在 64 位版本的 Windows 上运行。此头文件还标识了文件的类型:GUI、CUI 或 DLL,并包含一个时间戳,指示文件的构建时间。
- CLR 头 (CLR header) - 包含所需的 CLR 版本、入口点方法(Main 方法)、模块元数据的位置/大小、资源、强名称、标志等。
- 元数据表 (Metadata table) ——描述代码中的类型,包括每个类型的定义、每个类型成员的签名、代码引用的成员,以及运行时在执行时使用的其他数据。
- 托管代码 (Managed code) - 编译器在编译源代码时生成的代码
上述元数据始终与代码(MSIL)嵌入在同一个 EXE/DLL 中,无法分离。
加载 CLR
当运行一个可执行文件时,Windows 会检查该 EXE 文件的头部,以决定是创建 32 位还是 64 位的进程。一旦进程创建完成,Windows 还会进一步检查头部中嵌入的 CPU 架构信息,并据此将 MSCorEE.dll 加载到进程的地址空间中。
根据计算机中的 CPU 类型,Windows 会加载 x86、x64 或 ARM 版本的 MSCorEE.dll。
进程的主线程调用 MSCorEE.dll 中的一个方法,该方法初始化 CLR,加载 EXE 程序集,并调用其入口点方法(Main)。此时,托管应用程序便启动并运行了。
JIT 与执行
JIT (just-in-time) 编译在应用程序运行时,按需将程序集加载并执行的内容所对应的中间语言 (MSIL) 转换成本机代码。由于 MSIL 是“即时”编译的,CLR 的这一组件常被称为 JITter 或 JIT 编译器 (JIT compiler)。
JIT 编译会考虑到某些代码在执行过程中可能永远不会被调用的情况。它不会耗费时间和内存将 PE 文件中的所有 MSIL 转换为本地代码,而是在执行过程中根据需要转换 MSIL,并将生成的本地代码存储在内存中,以便在该进程的上下文中供后续调用使用。
以下图为例介绍一下执行流程:
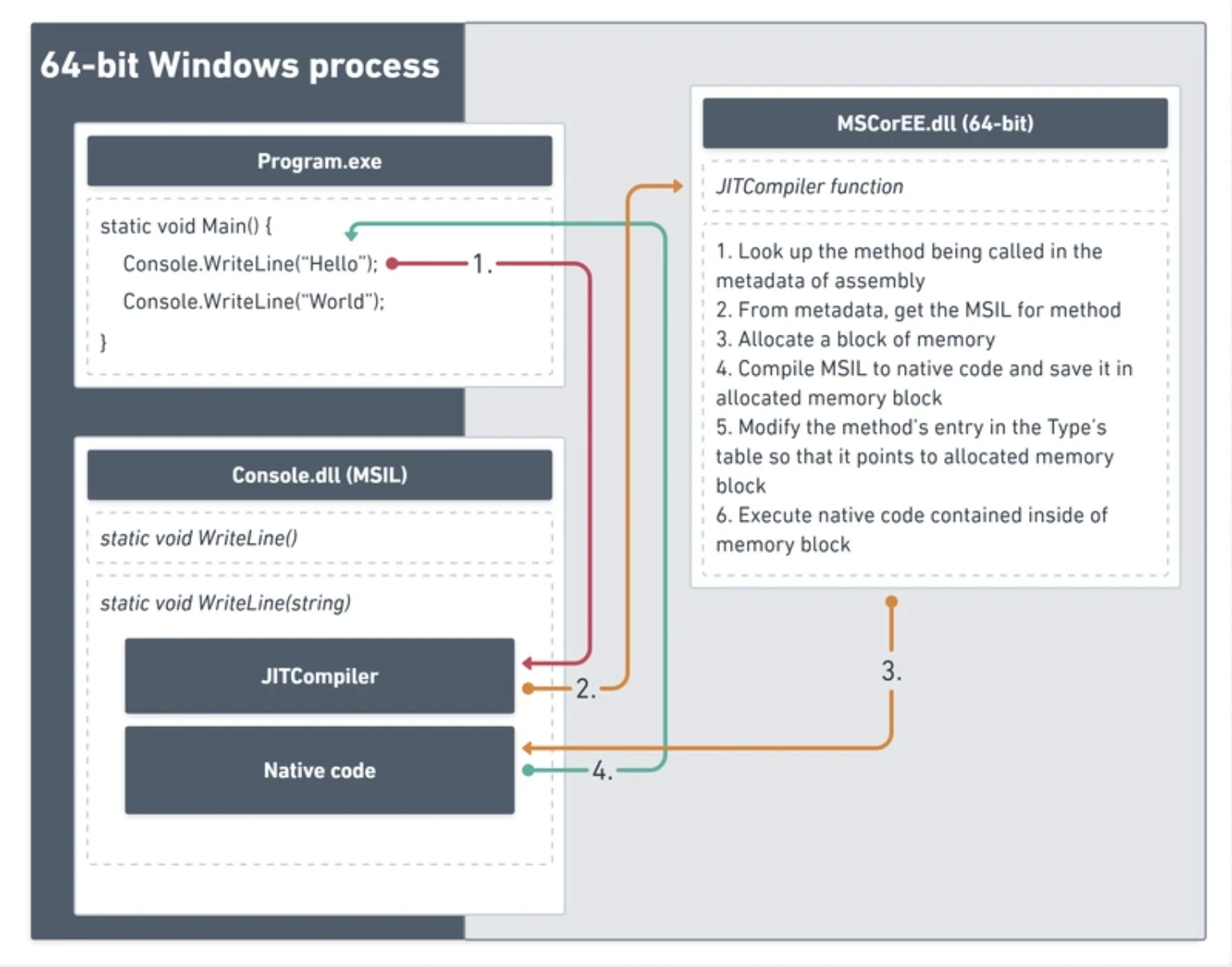
Program.exe执行时,调用Console.WriteLine("Hello")- 找到对应的
Console.dll中的WriteLine(string)(MSIL格式) - 调用 JIT 编译器(是
MSCorEE.dll的一部分)去验证并编译这个方法 - 把 IL 编译为 Native Code,即机器语言;其被保存在动态分配的内存块中
- 修改类型表的指针指向 Native Code 所在内存块的地址(这样下次调用就不再编译)
- 直接执行 Native Code,执行完成后返回
Program.exe的Main方法,继续执行
第二次执行 WriteLine 时, WriteLine 方法的代码已经过验证和编译,这意味着方法调用可以直接指向存储本机代码的内存块。
验证
在将 MSIL 编译为本机代码时,CLR 会执行一个称为验证的过程,以确保代码的所有操作都是安全的。例如,验证会检查每个方法是否以正确数量的参数调用,传递的每个参数是否为正确类型,每个方法的返回值是否正确使用,每个方法是否有返回语句等。
.NET 是什么

Java
Java 关键组件
- JDK(Java 开发工具包)
- JDK 包括 JVM(Java 虚拟机)和 JRE(Java 运行时环境),以及开发所需的基本工具,如编译器( javac )。它允许开发者编写、编译和执行 Java 程序。
- JVM(Java 虚拟机)
- JVM 是运行 Java 字节码的引擎。
- 字节码是一种二进制格式,对所有操作系统都相同。这种字节码可以在任何拥有 JVM 的平台上执行,确保了平台独立性。
- JRE(Java 运行时环境)
- JRE 提供了运行 Java 程序所需的库和资源,其中包括 JVM。
- 它包含了诸如 String 和 Array 等核心类,这些类可能是 Java 程序所依赖的。
- JRE 不包含编译器这样的开发工具,因此它适合运行 Java 应用程序,但不适合进行开发。
- 例如执行
java --version能够正确返回版本,但是执行javac HelloWorld.java却返回找不到命令,就可能是电脑上有运行时环境,但是没有安装 JDK。
- 例如执行
Java 执行过程

总体感觉和 C# 类似。
- 编写代码
- 编译代码:代码准备就绪后,使用
javac编译器将人类可读的.java代码转换为字节码(存储在.class文件中)。 - 使用 JVM 执行字节码
- 加载字节码
- JVM 会将字节码(即
.class文件)加载到内存中。 - 类加载器负责根据用户提供的类名查找并加载类。
- 果找不到该类,则会抛出
ClassNotFoundException。 - 如果找到该类,JVM 会将其加载到内存中。类的静态方法、变量和数据存储在方法区,这是 JVM 内存中的一个特殊部分。
- 果找不到该类,则会抛出
- JVM 会将字节码(即
- 执行字节码:类加载完成后,JVM 会寻找
main()方法(程序的入口点)开始执行。
- 加载字节码
执行机制
- 解释器(较慢)
- 在解释器方法中,JVM 逐行读取并执行字节码。每次调用方法时,JVM 都会重新解释字节码。
- JIT(即时)编译器(更快)
- JIT 编译器将字节码编译为本地机器码,这些机器码特定于程序运行的平台和机器。编译后的机器码会被缓存,因此当再次需要相同的方法时,JVM 可以直接使用缓存的机器码,从而加快执行速度。
JVM 内存区域
JVM 在执行过程中为程序的不同部分分配内存。一些关键区域包括:
- 方法区:存储类、方法和静态变量的信息。
- 堆区:存储运行时创建的对象。
- 栈区:存储局部变量和方法调用。
- 程序计数器(PC):一个指向当前正在执行指令的寄存器。
Python
Python 解释器
Python 解释器分为多种类型,每种都旨在优化语言的关键特性。
- 默认的实现是 CPython,它支持广泛的库,具有跨平台兼容性,并且拥有非常活跃的用户社区。如果你刚刚在机器上安装了 Python,并想通过一个简单的
print("Hello World!")测试它是否正常工作,那么你使用的就是 CPython。 - PyPy 是一款高性能的 Python 解释器,采用即时(JIT)编译技术。JIT 编译器通过在运行时将字节码转换为本地机器码,从而提升 Python 程序的执行效率。它为长时间运行的应用程序提供了更快的执行速度,同时保持与 CPython 的兼容性,并为大型应用带来内存使用上的高效性。
- 接下来是 Jython,这是一个用 Java 编写的 Python 解释器,专为在 Java 平台上运行而设计。它提供了与 Java 库的无缝连接、真正的多线程能力,以及与 Java 生态系统的简单接口。
Python 解释器工作流程
和 Java 的处理流程也挺类似的,不过 Python 解释器没有显式地展现中间字节码的生成步骤。
- 源代码分析:解释器遵循缩进规则并检查 Python 语法。如果存在一些错误的行,那么程序会停止并且输出错误信息。这一阶段称为词法分析,即将源代码文件分割成一系列 token。
- 字节码生成
- Python 解释器的解析器接收到 token 后,便开始处理这些词法 token (lexical token)。它会生成一个称为 AST(抽象语法树)的大型结构。
- 解释器将这个抽象语法树转换为字节码,也就是机器语言。在 Python 中,字节码可以保存为以
.pyc为扩展名的文件。
- Python 虚拟机(PVM):解释器加载包含库模块的机器语言,并将其输入到 PVM 中。PVM 将字节码转换为可执行代码,如 0 和 1(二进制)。



